
Data Analytics – Von der Datenerfassung zur Entscheidungsunterstützung

Wenn wir uns die vergangenen Jahrzehnte anschauen, wird eines ziemlich klar: Daten haben enormen Einfluss, egal ob es sich um kleine Mengen an Daten, Big Data, klassische oder moderne Statistik, Analytik oder gar künstliche Intelligenz handelt – und das betrifft Mitarbeiter:innen auf allen Unternehmensebenen. Daten helfen auf vielfältige Art und Weise, die Unternehmensleistung zu verbessern.
Auf der einen Seite haben wir künstliche Intelligenz, von der wir uns versprechen, Geschäftsmodelle komplett zu verändern und die deshalb die meiste Aufmerksamkeit bekommt. Auf der anderen Seite sind schon einfache Analysen mit wenigen Daten äußerst wirkungsvoll, wenn es darum geht, Unternehmen dabei zu unterstützen, bessere Entscheidungen zu treffen, Geschäftsabläufe zu steuern und zu optimieren, ein besseres Verständnis für Kunden zu bekommen und Produkte sowie Dienstleistungen zu verbessern.
Die Nutzung von Daten zur Informationsgewinnung und Entscheidungsunterstützung hat sich zu einer zentralen Säule in vielen Unternehmen entwickelt. Data Analytics bietet die Möglichkeit, aus Daten wertvolle Erkenntnisse zu gewinnen, Geschäftsprozesse zu optimieren und fundierte Entscheidungen zu treffen. In diesem Beitrag stelle ich Ihnen die vier Analytics-Reifegradstufen nach Gartner vor und wie das Vorgehensmodell des CRISP-DM (Cross-Industry Standard Process for Data Mining) einen strukturierten Rahmen bieten kann, um den größtmöglichen Nutzen aus Daten zu ziehen.
Analytics-Reifegradstufen nach Gartner
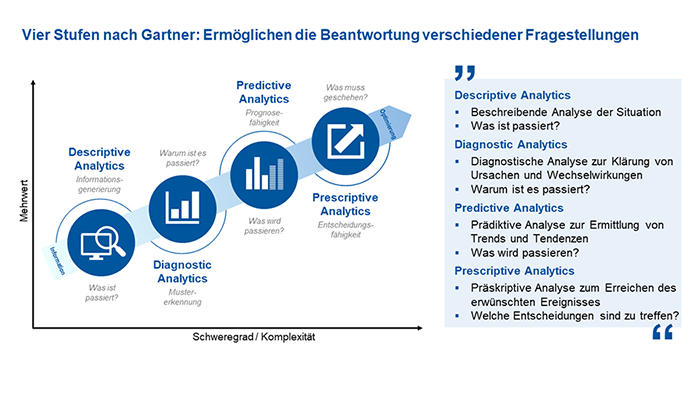
Die Unternehmensberatung Gartner Inc. hat im Jahr 2012 Forschungsergebnisse vorgestellt, die es bis heute anschaulich ermöglichen, Data Analytics in vier Reifegradstufen zu unterteilen. Hierzu zählen:
- Deskriptive Analytics
Deskriptive Analytics ist der Ausgangspunkt jeder Datenanalyse und beschreibt vergangene Ereignisse. Hierbei sammeln die Beteiligten historische Daten und nutzen diese, um überhaupt erst einmal zu verstehen, „Was ist passiert?“. Diese Phase legt den Grundstein für das Verständnis der eigenen Datenlandschaft und ermöglicht erste Einblicke in vergangene Entwicklungen. - Diagnostic Analytics
In der zweiten Reifegradstufe beschreibt Diagnostic Analytics die Identifizierung von Mustern und Trends in den Daten. Wenn diese erkannt wurden, geht es darum, die Gründe hinter den Ereignissen zu verstehen. Basierend auf der Frage „Warum ist es passiert?“ analysieren die Verantwortlichen Zusammenhänge und Kausalitäten, um beispielsweise Ursachen für Qualitätsprobleme oder Engpässe in Geschäftsprozessen aufzudecken. - Predictive Analytics
Predictive Analytics ist die erste in die Zukunft gerichtete Stufe. Es werden historische Daten genutzt, um zukünftige Entwicklungen vorherzusagen. Statistische Modelle und Machine-Learning-Algorithmen ermöglichen Prognosen, die als Grundlage für vorausschauende Entscheidungen dienen und der Frage nachgehen „Was wird passieren?“. - Prescriptive Analytics
Stufe vier ist die höchste Stufe der Data Analytics: Prescriptive Analytics geht über die Vorhersage hinaus und empfiehlt konkrete Handlungsschritte, indem sie fragt, „Was muss geschehen?“. Basierend auf den Erkenntnissen der vorherigen Stufen schlägt sie Maßnahmen vor, um gewünschte Ziele zu erreichen.
Maoz, Michael: How IT Should Deepen Big Data Analysis to Support Customer-Centricity. Gartner Research 2013.
Die Einteilung in die vier Stufen und ihre Leitfragen helfen Mitarbeiter:innen in Unternehmen insbesondere in der Praxis dabei, eine klare Struktur zu schaffen, um ihre Datenanalysestrategien zu gestalten und zu verbessern. Dies ermöglicht eine schrittweise Entwicklung von der reinen Datenerfassung bis hin zur datengestützten Entscheidungsfindung.
Durch diese Einteilung können Unternehmen gezielt in die jeweiligen Stufen investieren, um die Leistung ihrer Geschäftsprozesse zu steigern. Die Vorteile liegen in der schrittweisen Steigerung der Analysekomplexität, von retrospektiven Einblicken bis hin zu proaktiven Handlungsempfehlungen. Dadurch können sie nicht nur Vergangenes besser verstehen lernen, sondern auch zukünftige Trends vorhersagen und schließlich fundierte Maßnahmen ableiten, um ihre Ziele effizient zu erreichen und ihre Wettbewerbsfähigkeit zu stärken.
Der CRISP-DM-Prozess in der Data Analytics
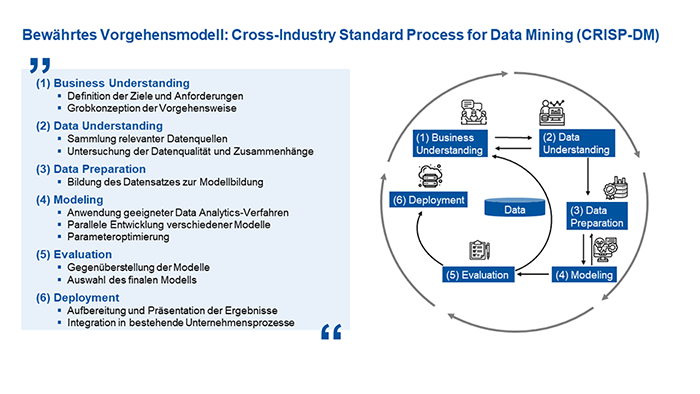
Das CRISP-DM-Vorgehensmodell (CRoss Industry Standard Process for Data Mining) bietet einen bewährten Rahmen für den Datenanalyseprozess in Unternehmen. Es ist in folgende sechs Phasen unterteilt:
- Business Understanding
Die Phase des Business Understanding dient dazu, zu Beginn klare Geschäftsziele und Anforderungen festzulegen. Dabei definieren die Beteiligten die grundlegenden Fragen, die durch die Datenanalyse beantwortet werden sollen. Hierbei steht im Fokus, wie die Daten zur Erreichung der Unternehmensziele beitragen können. - Data Understanding
In der Phase des Data Understanding geht es darum, verfügbare Datenquellen zu analysieren und zu verstehen. Die Untersuchung der Datenqualität und deren Zusammenhänge sind zentrale Aufgaben und Ziele in dieser Phase. - Data Preparation
Anschließend erfolgt die Data Preparation: Daten werden bereinigt, transformiert und aggregiert, um sie für die Modellbildung vorzubereiten. - Modeling
Während des Modeling erfolgt die Anwendung geeigneter Data-Analytics-Verfahren. Hierbei können verschiedene Modelle auch parallel entwickelt und erprobt werden, um Muster und Zusammenhänge in den Daten zu identifizieren. - Evaluation
Die Evaluation dient dazu, die erstellten Modelle auf ihre Leistung und Ergebnisse zu überprüfen und zu vergleichen. Als Ergebnis soll eine Auswahl des finalen Modells erfolgen. Hierbei ist es wichtig zu erwähnen, dass es zu einem Closed-Loop kommt, in dem die Ergebnisse mit den Zielen und Anforderungen des Business Understanding abgeglichen werden. Bei Abweichungen, die durchaus auch positive Erkenntnisse und Verbesserungen sein können, erfolgen die weiteren Phasen iterativ. - Deployment
In der letzten Phase des Deployment steht im Fokus, die am besten geeigneten Modelle zu implementieren und in die Geschäftsprozesse zu integrieren. Die implementierten Modelle sollten kontinuierlich überwacht werden, um sicherzustellen, dass sie effektiv arbeiten.
Chapman, Pete et al.: CRISP-DM 1.0: Step-by-step data mining guide. SPSS Inc. 2000.
Die Verknüpfung der vier Reifegradstufen nach Gartner mit den Phasen des CRISP-DM schafft einen leistungsstarken Rahmen für den effektiven Einsatz von Data Analytics. Von der explorativen Analyse der Vergangenheit bis zur präskriptiven Handlungsempfehlung für die Zukunft bietet dieser Ansatz ein umfassendes Vorgehensmodell, um Daten in konkrete und strategische Entscheidungen umzuwandeln.
Fazit
Data Analytics ist heute mehr denn je ein entscheidender Faktor für den Geschäftserfolg. Die systematische Orientierung an den oben genannten Reifegradstufen und die strukturierte Anwendung des CRISP-DM als Vorgehensmodell ermöglichen es Unternehmen, von der Datenerfassung zur wirkungsvollen Handlungsempfehlung zu gelangen. Egal, ob es um die Optimierung der Produktqualität, Prozesseffizienz oder die Vorhersage von Kundentrends geht – Data Analytics bietet eine reichhaltig wachsende Quelle für fundierte Entscheidungen und Innovationspotenzial.
Wie weit sind Sie in Ihrem Unternehmen mit der Anwendung von Data Analytics fortgeschritten? Teilen Sie uns Ihre Erfahrungen mit!
Autor:
Sebastian Beckschulte ist wissenschaftlicher Mitarbeiter am Lehrstuhl für Fertigungsmesstechnik und Qualitätsmanagement am WZL der RWTH Aachen. In der Abteilung Quality Intelligence entwickeln er und seine Kolleg:innen in den Bereichen der Produkt- und Prozessqualität bestehende Ansätze weiter und beantworten bekannte, unternehmerische Problemstellungen mit neuen Methoden und Technologien. Nach seinem Studium zum Wirtschaftsingenieur an der Universität Duisburg-Essen schlug Sebastian Beckschulte am Lehrstuhl eine wissenschaftliche Laufbahn ein. Als wissenschaftlicher Mitarbeiter setzt er sich dabei intensiv mit den Themen der datenbasierten Entscheidungsunterstützung in Fehlermanagement- und Produktionsprozessen auseinander.
Interview: Wie KI-Algorithmen zu einer verbesserten Qualitätskontrolle verhelfen

Inwiefern stellt die Automatisierung von Qualitätskontrollen mittels KI-Algorithmen eine nützliche Innovation für Unternehmen dar?
Qualitätskontrollen werden in den meisten Fällen stichprobenbasiert in Form einer Statistischen Prozesskontrolle (SPC) durchgeführt. Gründe hierfür sind hohe manuelle Aufwände bei den Qualitätsprüfungen, nicht existente Daten bzw. bei vorhandenen Daten eine fehlende Data Analytics-Infrastruktur, um eine Qualitätskontrolle auf einer Gesamtpopulation automatisiert durchzuführen. (mehr …)
Verbesserung der Vorhersagequalität von KI-Modellen mittels GANs (Generative Adversarial Neural Networks)

Die immer weiter steigende Leistungsfähigkeit von Convolutional Neural Networks (CNN) macht diese Architekturen für verschiedene Bildverarbeitungsaufgaben immer attraktiver. Sie werden nun verstärkt im Bereich der Bildverarbeitung eingesetzt. Insbesondere bei Bildklassifikationsaufgaben löst diese Technologie klassische analytische Bildverarbeitungsansätze ab. Steigende Datenverfügbarkeit und zunehmende Rechnerkapazitäten ermöglichen die hohe Leistungsfähigkeit und Anwendbarkeit dieser Modellarchitekturen.
Funktionsweise und Konzeption von CNNs
Bei der Bildklassifikation wird ein Eingangsbild entsprechend einer Menge von möglichen Klassen zugeordnet. Durch einen Trainingsprozess mit einer ausreichenden Datenmenge werden die Parameter der Modellarchitekturen so angepasst, dass sie die gestellte Aufgabe mit möglichst wenigen Fehlklassifikationen erfüllen können. Die Modelle lernen aus den Daten. Bekannte Bildklassifizierungsarchitekturen wie AlexNet1, VGG-162, ResNet3, Inception-V34 und Efficientnet5 nehmen ein Eingangsbild und leiten es dann durch mehrere Schichten. Aufgrund der hohen Anzahl an Parametern dieser Architekturen wird eine große Menge an repräsentativen Daten benötigt, um ihre Leistung und Generalisierungsfähigkeit zu verbessern.
Die Architekturen sind in der Regel so konzipiert, dass sie mit ausgewogenen Datensätzen gut funktionieren. Ein häufig auftretendes Problem bei realen Datensätzen ist, dass sie unter einem Ungleichgewicht der Klassen leiden. Bei der Qualitätskontrolle in der Produktion steht oft nur eine kleine Anzahl von Defektbildern zum Trainieren der CNNs zur Verfügung, wohingegen viele Gutbilder vorhanden sind. Dies führt zu dem Problem, dass die Netze allein auf Grund der Unausgewogenheit der Daten dann dazu neigen, ein Bild eher als Gutbild zu klassifizieren als als Defektbild, da dieser Vorgang im Trainingsprozess meist zu einer korrekten Klassifizierung führte und somit mit einem kleinen Loss belohnt wurde.
Gängige Ansätze Klassenungleichgewicht auszugleichen
Es gibt verschiedene Methoden dieses Ungleichgewicht zu reduzieren oder zu kompensieren. Eine häufig verwendete Methode ist die Datenaugmentierung. Dabei werden leicht modifizierte Kopien von bereits vorhandenen Daten erstellt und zu der entsprechenden Klasse hinzugefügt. Eine weitere Möglichkeit ist die Anpassung der Gewichtung. In diesem Fall werden Fehlklassifikationen von Instanzen aus Klassen mit wenig Daten stärker gewichtet.
Fähigkeiten und Möglichkeiten von Generative Adversarial Networks
Im Gegensatz zu den genannten Ansätzen zielen Generative Adversarial Neural Networks (GANs) in diesem Kontext darauf ab, die zugrundeliegenden Datenverteilungen aus den begrenzten verfügbaren Bildern zu lernen und dann die gelernten Verteilungen zu verwenden, um synthetische Bilder zu erzeugen. Dies wirft die interessante Frage auf, ob GANs verwendet werden können, um synthetische Bilder für Klassen mit wenig Bilddaten verschiedener unausgeglichener Datensätze zu erzeugen. Sie könnten somit als eine intelligente Oversampling-Methode verwendet werden. GANs sind nicht nur in der Lage ein synthetisches Bild zu generieren, sondern bieten auch eine Möglichkeit, etwas am Originalbild zu verändern.
Wie funktionieren GANs?
Generative Adversarial Networks bestehen aus zwei künstlichen neuronalen Netzen. Ein Netz ist der sogenannte Generator, der aus einem Vektor latenter Variablen künstliche Daten erzeugt. Das zweite Netz ist der Diskriminator, der die Daten auswertet und versucht, zwischen künstlichen und realen Daten zu unterscheiden. Diese beiden Netzwerke führen im Trainingsprozess ein Nullsummenspiel durch6.
Der Generator versucht, Daten zu erzeugen, die den realen Daten so ähnlich sind, dass der Diskriminator nicht in der Lage ist, die künstlich erzeugten Daten von den realen Daten zu unterscheiden. Abbildung 1 zeigt eine schematische Darstellung einer klassischen GAN-Architektur.
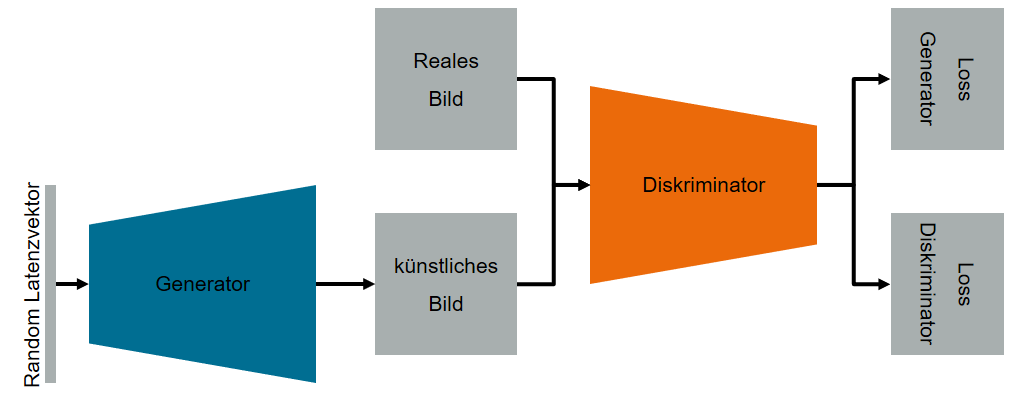
Abbildung 1: Schematische Darstellung einer klassischen GAN-Architektur. Quelle: Janek Stahl
Die ersten GAN-Architekturen benötigten eine große Menge an Daten für die Trainingsphase und konnten nur Bilder mit begrenzter Auflösung erzeugen. Neuere Architekturen wie SinGAN7 oder StyleGAN28, die mit Adaptive Discriminative Augmentation (ADA) arbeiten, erlauben es jedoch, auch mit kleinen Datensätzen hochwertige Bilder zu erzeugen.
Realistische Bilder auch bei begrenzten und unausgewogenen Datensätzen
Um eine möglichst realitätsnahe Situation zu simulieren, wurde ein Teildatensatz des MVTech Anomaly Detection Datensatzes9 betrachtet. Im Speziellen wurde der Datensatz “carpet” und der Datensatz “hazelnut” für Untersuchungen mit GAN-Architekturen verwendet. Jeder Datensatz enthält fehlerfreie Bilder der Klasse “no-defect“ und Bilder mit Anomalien der Klasse „defect“. Die Bilder wurden so aufgeteilt, dass im Trainingsdatensatz nur 10 Bilder der Minoritäten-Klasse „defect“ und 280 Bilder der Klasse „no-defect“ vorliegen. Somit handelt sich also um stark unausgeglichene Datensätze.
In einer ersten Untersuchung wurde die SinGAN-Architektur verwendet. Diese Architektur ist in der Lage, durch Training mit nur einem Bild künstliche Bilder zu erzeugen. Nach einer Trainingszeit von nur sechs Stunden war das Modell in der Lage, realistische Defektbilder des Datasets “carpet” zu erzeugen. Für das komplexere Objekt Haselnuss des Datasets “hazelnut” war dies mit dieser Architektur nicht möglich.
In einer zweiten Untersuchung wurde die StyleGAN2-Architektur verwendet. Hier wurde das Netz mit den 280 Bildern ohne Anomalien und mit den 10 Bildern mit Anomalien trainiert. Nach einer Trainingszeit von etwa einer Woche war die Architektur in der Lage, qualitativ hochwertige Bilder zu generieren. Dies gelang sowohl für den “carpet”- als auch für den “hazelnut”-Datensatz. Tabelle 1 zeigt reale Bilder der Datensätze und künstlich erzeugte Bilder der Datensätze.

Tabelle 1: Echte Bilder des Datensatzes und künstlich generierte Bilder der Datensätze.
Künstliche Bilder der Minoritäten-Klasse „defect“ wurden dann dem Trainingsset der CNNs hinzugefügt. Die Auswertungen der trainierten CNN-Modelle hat gezeigt, dass die CNNs, welche mit künstlich generieten Bilder in der Klasse „defect“ trainiert wurden eine höhere Vorhersagezuverlässigkeit aufweisen als die CNNs, welche ohne die künstlich generierten Bilder trainiert wurden.
Zusammenfassung
Diese Untersuchung hat gezeigt, wie einige der neuesten GAN-Architekturen in der Lage sind, selbst bei begrenzten und unausgewogenen Datensätzen qualitativ hochwertige Bilder zu erzeugen. Der Einsatz dieser Architekturen kann dazu beitragen, das Zuverlässigkeitsniveau von automatischen Systemen zur Anomalieerkennung auf Basis von Deep Learning zu erhöhen. Tatsächlich kann die Integration von synthetisch erzeugten Bildern in den Datensatz es ermöglichen, das Genauigkeitsniveau des Qualitätsprüfungssystems auch in Kontexten zu erhöhen, in denen es aufgrund der geringen Häufigkeit von Anomalien schwierig ist, eine große Menge an ausgewogenen realen Daten zu generieren.
[1] Alex Krizhevsky, Sutskever, I. and Hinton, G. E., [ImageNet Classification with Deep Convolutional Neural Networks], Curran Associates, Inc, 1097–1105 (2012).
[2] Simonyan, K. and Zisserman, A., [Very Deep Convolutional Networks for Large-Scale Image Recognition] (9/4/2014).
[3] He, K., Zhang, X., Ren, S. and Sun, J., “Deep residual learning for image recognition,“, 770–778.
[4] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. and Wojna, Z., “Rethinking the inception architecture for computer vision,“, 2818–2826 (2016).
[5] Tan, M. and Le, Q., “Efficientnet: Rethinking model scaling for convolutional neural networks,“, 6105–6114 (2019).
[6] Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A. and Bengio, Y., “Generative adversarial networks,“ arXiv preprint arXiv:1406.2661 (2014).
[7] Shaham, T. R., Dekel, T. and Michaeli, T., “Singan: Learning a generative model from a single natural image,“, 4570–4580 (2019).
[8] Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J. and Aila, T., “Analyzing and improving the image quality of stylegan,“, 8110–8119 (2020).
[9] Bergmann, P., Fauser, M., Sattlegger, D. and Steger, C., “MVTec AD‐A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection,“, 9592–9600 (2019).
Über die Autoren:
Janek Stahl ist seit 2015 als wissenschaftlicher Mitarbeiter am Fraunhofer-Institut für Produktionstechnik und Automatisierung tätig. Seit seinem Maschinenbaustudium an der Universität Stuttgart arbeitet er dort in der Abteilung Bild- und Signalverarbeitung, wo er sich verstärkt mit maschinellen Lernverfahren für die 2D-Bildverarbeitung im industriellen Umfeld beschäftigt.
Omar De Mitri ist seit 2019 wissenschaftlicher Mitarbeiter am Fraunhofer-Institut für Produktionstechnik und Automatisierung. Seit Abschluss seines Studiums des Computer Engineering an der Universität Salento (Italien) arbeitet er dort in der Abteilung Bild- und Signalverarbeitung. Sein besonderes Interesse gilt dem maschinellen Lernen mit Schwerpunkt im Bereich Computer Vision und Mustererkennung.
Optimierung von Produktionsprozessen mit Hilfe der Digitalisierung: Herausforderungen bei der Auswahl geeigneter Messsysteme

Leistungsstarke Algorithmen und Rechenkapazitäten ermöglichen den Einsatz und die Auswertung einer Vielzahl von Sensoren. Dadurch erhoffte Verbesserungen in der Produktion von Gütern (z.B. Qualitätsoptimierung, Senkung von Prozesszeiten) können lediglich erzielt werden, wenn bereits die Basis, also die aufgenommenen Daten, eine ausreichende Güte aufweisen. Bei der Aufnahme von Prozessdaten hinsichtlich der Auswahl geeigneter Messsysteme gilt es, verschiedene Herausforderungen zu meistern, um die Güte der Daten sicherzustellen und somit die Ansätze von Industrie 4.0 voll zur Entfaltung kommen zu lassen. (mehr …)
KI-basierte Bildverarbeitung in der Qualitätssicherung

Künstliche Intelligenz (KI) hat in den vergangenen Jahren insbesondere in der Bildverarbeitung ihr hohes Potenzial gezeigt. Allgemein bekannt sind hier vor allem Klassifizierungsaufgaben, wie beispielsweise die Unterscheidung zwischen Hunde- und Katzenbildern [Golle 2008]. Im industriellen Umfeld findet man Klassifizierungsaufgaben insbesondere in der Qualitätssicherung (QS). Die in der Bildverarbeitung eingesetzten KI-Methoden sind vor allem aus dem Bereich des maschinellen Lernens (ML) und können den überwachten Lernverfahren zugeordnet werden. Unüberwachte Lernverfahren spielen hier eine eher untergeordnete Rolle. (mehr …)
Blick in die Black Box: Erklärbarkeit maschineller Lernverfahren

In den letzten Jahren hat das maschinelle Lernen (ML) als Teildisziplin der künstlichen Intelligenz in vielen Bereichen, wie etwa der Produktion oder Medizin, verstärkt an Bedeutung gewonnen. Immer wichtiger wird dabei das sogenannte Deep Learning, das heißt das Training tiefer künstlicher neuronaler Netze (KNN) mittels großer Datensätze für eine bestimmte Aufgabe. Oftmals übertreffen Modelle, die durch Deep Learning erstellt wurden, sogar den Menschen (OpenAI 2019). Allerdings stellen viele ML-Verfahren, und hierzu zählen auch die gerade genannten tiefen KNN, eine Art „Black Box“ dar. Das bedeutet, dass getroffene Entscheidungen dieser Verfahren aufgrund komplexer interner Prozesse für den Menschen – selbst für Experten – oft nicht nachvollziehbar sind. (mehr …)
Big Data in der Kunststoffverarbeitung

Zerstörungsfreie Prüfmethoden beim Compoundieren
Die Überwachung von Produktionsprozessen und die dabei auftretende Generierung und Verarbeitung großer Datenmengen (Big Data) hat in den letzten Jahren zunehmend an Wichtigkeit gewonnen und führt letztlich zu einem verbesserten Qualitätsstandard vieler Produkte. In der Kunststoffbranche bestehen insbesondere beim Compoundieren, der Basis für die sich daran anschließenden, formgebenden Verarbeitungsverfahren, hohe Ansprüche bezüglich der Prozesskontrolle und der dafür notwendigen Messverfahren zur Informationsgewinnung über den Ist-Zustand. Seit Langem etabliert sind hierbei Druck- und Temperaturmessungen. Moderne Messmethoden bieten aber weit darüber hinausreichende Möglichkeiten. (mehr …)
Was ist Künstliche Intelligenz?

Künstliche Intelligenz (KI) und Big Data sind Schlagwörter, die aktuell in Fachmedien sehr präsent sind. Doch was genau ist eine KI und wofür wird sie eingesetzt? Welche Verbindung besteht zwischen Big Data und KI?
Dieser Beitrag stellt die grundlegende Funktionsweise von KI vor. Es werden Beispiele für KI im Alltag, sowie Möglichkeiten der Anwendung von KI in Wertschöpfungsnetzwerken aufgezeigt und welche Verbindung zwischen KI und Big Data besteht. (mehr …)
Daten werden zum Wirtschaftsgut – Unternehmen auf dem Weg in die Datenökonomie
In unserer Gesellschaft spielen Daten, die wir durch Messung oder Beobachtung erhalten, eine zentrale Rolle. Nicht umsonst gelten sie als das neue Öl unserer Zeit. Dies betrifft sowohl die Daten, die tagtäglich über uns gesammelt werden, als auch Daten, Kennzahlen und Messwerte im unternehmerischen Kontext. Durch neue und rasante technologische Entwicklungen wächst die verfügbare Datenmenge aus allen Geschäftsbereichen eines Unternehmens stetig an. Doch was fängt man mit diesen Daten an und welchen Nutzen können Unternehmen aus ihnen ziehen? Inzwischen geht es nicht mehr nur darum, vorhandene Daten sinnvoll zu nutzen – zum Beispiel zur Fehlerbehebung oder Prozessoptimierung. Daten selbst werden zur Ressource und zum Wirtschaftsgut. Datenökonomie bedeutet, Daten in eigenständigen Geschäftsmodellen zu kommerzialisieren.
Zukunftsfähig und praxisnah – wie die DGQ und ihre Trainer neue Lehrgänge entwickeln

Die Welt der Weiterbildungsangebote wandelt sich schnell und kontinuierlich. Denn neue Trends, Methoden und Techniken in der Arbeitswelt liefern Anlässe, Themen stetig neu zu denken und Trainingsformate auf die Herausforderungen der Zukunft auszurichten. Bei der Entwicklung neuer DGQ-Trainings leisten Trainer einen entscheidenden Beitrag. Sie wirken bei der Entwicklung neuer Lehrgänge, Seminare und DGQ-Praxiswerkstätten mit und überarbeiten regelmäßig bestehende Formate.
(mehr …)
Big Data bei vielen Unternehmen an erster Stelle
Neue Technologien, wie das Internet of Things, künstliche Intelligenz oder Block Chain haben einen immer größeren Einfluss auf die Wettbewerbsfähigkeit von Unternehmen. Das besagt eine repräsentative Befragung von Managern in 604 deutschen Unternehmen ab 20 Mitarbeitern, die der Digitalverband Bitkom 2018 durchgeführt hat. Ein zentrales Ergebnis: Big Data steht an erster Stelle der geplanten oder bereits umgesetzten Technologien (57 Prozent).
(mehr …)
Digitalisierung – so ändern sich die Anforderungen an Datenerhebung und statistische Methoden

Die Relevanz von Daten und deren Erhebung, Analyse und Interpretation stehen zunehmend im Zentrum digitalisierten Industrie und Gesellschaft. Neben dem Einsatz innovativer Technologien und der Entwicklung digitaler Geschäftsmodelle bietet die Analyse großer Datenmengen für Unternehmen bemerkenswertes Potenzial zur besseren Marktpositionierung.
DGQ-Statistik-Trainings: Lange Tradition in der Vermittlung statistischer Methoden

Für produzierende Unternehmen sind statistische Methoden für die Analyse von Produktionsprozessen seit jeher die Basis, um Prozesse und Produkte zu vebessern. Im Qualitätsmanagement oder in der Qualitätssicherung bilden die Voraussetzung für reproduzierbare Qualität. Durch geeignete statistische Methoden lassen sich Prozesse beherrschen und systematische Einflüsse von zufälligen Streuungen unterscheiden. Entlang des Produktionsprozesses haben sich in der Praxis eine Reihe von statistischen Verfahren als Werkzeuge etabliert.
Big und Smart Data – von der Statistik zur Datenanalyse
Statistik gehört zu unserem Alltag. Auch wenn wir nicht direkt im Berufsalltag mit statistischen Verfahren arbeiten, werden wir täglich mit einer Vielzahl von Statistiken konfrontiert: Wir erfahren über das Fernsehen, die Zeitung oder das Internet etwas über Aktienkurse, Trends auf dem Arbeitsmarkt, die aktuellen Wahlhochrechnungen oder die Auswertungen rund um die Fußball-Bundesliga. (mehr …)
