
Einsatz der Messmittelfähigkeit zur Absicherung von künstlicher Intelligenz

Künstliche Intelligenz hat sich in rasender Geschwindigkeit in vielen Bereichen der Wirtschaft durchgesetzt. Insbesondere große Sprachmodelle werden dabei in immer mehr Anwendungen integriert. Die Frage, die sich dabei stellt, ist: Wie können diese Systeme sinnvoll abgesichert werden? In diesem Fachbeitrag soll gezeigt werden, dass etablierte Fähigkeitsanalysen, wie MSA oder VDA Band 5 auf ein breites Spektrum von KI-Systemen anwendbar sind.
Ein Blick in die KI-Verordnung aus dem Jahr 2024 zeigt, dass für KI-Systeme im Hochrisikobereich (zum Beispiel bei Sicherheitsbauteilen oder in der Bildung) ein Nachweis über die Genauigkeit vorgeschrieben ist (siehe Art. 15 (2) KI-Verordnung). Dabei wird explizit die Zusammenarbeit mit „Metrologischen Behörden“ seitens der EU-Kommission herausgestellt. Momentan ist noch unklar, wie genau diese Zusammenarbeit aussehen wird. Es kann davon ausgegangen werden, dass sich Behörden, wie die Deutsche Akkreditierungsstelle für eine einheitliche Begriffsdefinition mit bestehenden Normenwerken stark machen werden. Von zentraler Bedeutung ist dabei eine einheitliche Definition von Messunsicherheit und die Eignung eines KI-Systems für eine gegebene Anwendung.
Momentan liegt ein großer Teil der medialen Aufmerksamkeit auf Transformermodellen. Dies führt dazu, dass Transformermodelle wie gpt-4, die die Basis für Anwendungen wie ChatGPT bilden, häufig mit KI gleichgesetzt werden. Tatsächlich haben viele Mitarbeiter der Qualitätssicherung aber bereits jahrelange Erfahrung mit KI-Systemen in ihrer Produktion. Ein gutes Beispiel hierfür sind automatische Kamerasysteme zur Bildklassifikation.
In vielen Firmen werden automatische Kamerasysteme als Prüfmittel eingesetzt. Kamerasysteme können sowohl messende Prüfungen vornehmen als auch attributiv eingesetzt werden. Für beide Fälle existieren gut beschriebene und etablierte Verfahren wie MSA oder der VDA Band 5 mit seinen entsprechenden Erweiterungen um die Fähigkeit solcher Systeme nachzuweisen (s. Measurement systems analysis, 4th edition 06.2010 und VDA Band 5, 3. Auflage, Juli 2021). Das bedeutet, dass für solche KI-Systeme bereits eine direkte Anwendbarkeit der Begriffe „Eignungsnachweis“ und „Messunsicherheit“ gegeben ist.
Etwas weniger offensichtlich ist die Situation bei großen Sprachmodellen, wie gpt-4. Hierbei können unterschiedliche Fälle beantwortet werden. Im ersten Fall wird das Sprachmodell eingesetzt, um einen Text durch einen Zahlenwert zu bewerten. Ein einfaches Beispiel ist die automatische Bewertung von Kundenfeedback, bei dem ein Freitext einer Sternebewertung zugeordnet wird. Um das Beispiel zu verdeutlichen wurde folgender Prompt 50 mal mit unterschiedlichen Modellgenerationen von OpenAI, der Herstellerfirma von ChatGPT, getestet:
„Ich möchte, dass du Trainingsfeedbacks auf einer Skala von 1 bis 10 bewertest. Wie würdest du folgendes Feedback bewerten: „Schönes Training, sympathischer Trainer, das Essen war für mich sehr salzig.“ Bitte antworte nur mit einer Zahl.“
Abbildung 1 zeigt den Werteverlauf der Ergebnisse für drei unterschiedliche Modellgenerationen. Es fällt auf, dass das neuere Modell gpt-4o-mini im Vergleich zu den Vorgängermodellen gpt-3.5 und gpt-4 nicht mehr streut zur Übersetzung des folgenden Feedbacks in eine Punktebewertung.
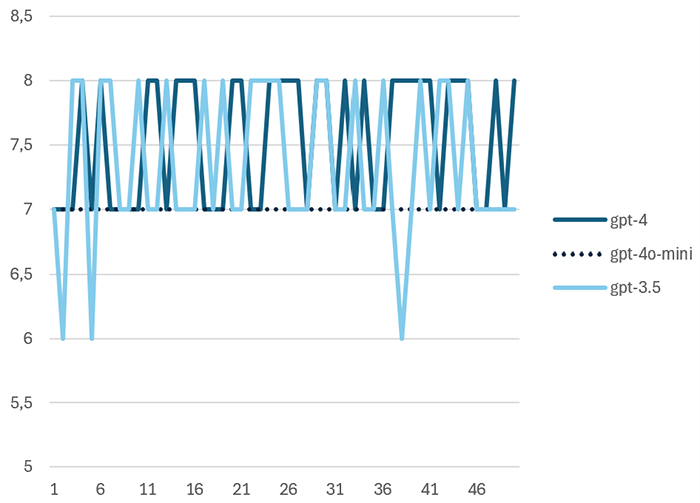
Abb. 1: Werteverlauf der Wiederholungsmessungen mit verschiedenen gpt-Modellen
Die Werteverläufe wurden mittels einer Messystemanalyse nach MSA und nach VDA Band 5 ausgewertet. Die Cg und Cgk-Werte wurden gemäß der VDA-Empfehlung ermittelt. Tabelle 1 zeigt die Übersicht der Ergebnisse. gpt-4o-mini hätte in diesem Fall die Fähigkeit nach VDA erreicht, scheitert allerdings an der aufgabenbedingten Auflösungsgrenze von 5 Prozent der Toleranz.
| gpt | x ̅ | s | Cg | Cgk | Qms |
|---|---|---|---|---|---|
| gpt-3.5 | 7,34 | 0,59 | 0,84 | 0,80 | 26,3% |
| gpt-4 | 7,54 | 0,50 | 0,99 | 0,74 | 23,1% |
| gpt-4o-mini | 7,00 | 0,00 | – | – | 11,5% |
Tab. 1: Ergebnisse der Fähigkeitsuntersuchungen für unterschiedliche Modellgenerationen
Ein Bereich, in dem die Bewertung von Text durch KI-Systeme eine hohe Relevanz hat, ist die Bildung. Ein gutes Beispiel hierfür ist die Firma Fobizz, die Software zur Unterstützung von Lehrkräften anbietet. Die Software von Fobizz wurde von den Bundesländern Mecklenburg-Vorpommern und Berlin lizensiert und steht dort allen Lehrkräften zur Verfügung. Pilotversuche in Bayern, Hessen und Baden-Würtemberg laufen. Ein Feature dieser Software ist die automatische Bewertung von Klassenarbeiten.
Rainer Mühlhoff und Marte Henningsen konnten in ihrem Vortrag auf dem Chaos Communications Congress 2024 zeigen, dass die Software bei mehrfacher Eingabe identischer Klausuren zu unterschiedlichen Bewertungsergebnissen kommt. Dies ist nicht überraschend, da es sich laut Auskunft der Firma um ein Webfrontend für ein großes Sprachmodell handelt. Eine Eigenschaft von Sprachmodellen ist, dass die Ausgabe üblicherweise innerhalb gewisser Grenzen zufällig variiert wird. Dies führt zu einer zufälligen Streuung in den Bewertungsergebnissen, die sich auch in Abbildung 1 gezeigt hat. Die Wissenschaftler konnten zeigen, dass die Benotung von einem Durchlauf zum nächsten um mehrere Notenschritte abweichen kann.
Ein interessanter Aspekt, der jedoch nicht untersucht wurde, ist die Frage, ob echte Lehrkräfte bei so einem Versuch besser abschneiden würden als das KI-System. Eine Auswertung nach Methode 2 mit zwei echten Lehrkräften und einem KI-System würde dies deutlich zeigen. So wäre es möglich zu entscheiden, ob das KI-System weniger streut als menschliche Lehrkräfte und ob es statistisch signifikante Abweichungen in Form von Bias zwischen dem KI-System und den Lehrern gibt. Tatsächlich fordert die KI-Verordnung genau solche Biasbewertungen als Teil der Absicherung für Hochrisiko-KI-Systeme.
Fobizz ist vorerst nicht zur Umsetzung statistischer Tests verpflichtet, weil die KI-Verordnung im Falle von Hochrisiko KI-Systemen nicht rückwirkend gilt. Voraussetzung ist dabei, dass das betroffene KI-System vor dem 02.08.2026 in Verkehr gebracht wurden und danach nicht wesentlich verändert wurden.
Die beiden obigen Beispiele zeigen, dass Prüfmittelfähigkeitsuntersuchungen für alle KI-Systeme anwendbar sind, die zur Kategorisierung oder Messung eingesetzt werden. Dies gilt selbst, wenn eine messende Bewertung eines Texts vorgenommen wird. Etwas anspruchsvoller ist der Fall der Bewertung eines reinen Chatbots. Da bei einem Chatbot sowohl Ein- als auch Ausgabe unstrukturierter Text ist, sind die statistischen Methoden der Qualitätssicherung hier nicht direkt einsetzbar. Dies ist Gegenstand aktueller Forschung. Das einfachste Vorgehen ist es Menschen einzusetzen, die bewerten, ob der Chatbot richtig reagiert hat und so den attributiven Eignungsnachweis zu führen. Als Mustereingaben können Chatverläufe genutzt werden, die in der Vergangenheit zu Auffälligkeiten geführt haben. Das Vorgehen ist dabei ähnlich wie bei Grenzmustern mit bekanntem Gut-/Schlechtentscheid in der Kameraprüfung.
Da bei diesem Vorgehen die Unsicherheit der menschlichen Einschätzung und die zufällig streuende Antwortqualität der Maschine mathematisch nicht unterscheidbar sind, kann der Eignungsnachweis hier deutlich schwieriger sein. In jedem Fall sollten statistische Methoden eingesetzt werden, um ausreichend hohe Stichprobenumfänge mit einer aussagekräftigen Anzahl an Wiederholungen festzulegen.
Zusammenfassung
Es wurde gezeigt, dass Methoden, wie die Prüfmittelfähigkeit sich in vielen Fällen direkt auf die Eignung von KI-Systemen anwenden lassen. Dies gilt auch für viele andere statistische Verfahren der Qualitätssicherung, wie zum Beispiel F- und t-Tests oder Kreuztabellenbetrachtungen. Durch den Einsatz anerkannter Bewertungsverfahren steigt das Vertrauen in das KI-System und die Genauigkeit der Systeme kann in transparenter Weise ausgewiesen werden.
Die Bedeutung von Eignungsnachweisen für KI-Systeme wird durch die Anforderungen der KI-Verordnung deutlich steigen. Es muss jedoch betont werden, dass viele Normen, die die praktische Umsetzung der KI-Verordnung beschreiben, aktuell noch in Erstellung sind. Bereits jetzt steht allerdings fest, dass die Qualitätssicherung einen wertvollen Beitrag dazu leisten kann, präzise KI-Systeme zu entwickeln und zu betreiben. Mitarbeiter der Qualitätssicherung können auf diese Weise ihre einzigartigen Fähigkeiten nutzen und neue Werte für ihr Unternehmen schaffen.
Lesen Sie mehr zum Thema “Künstliche Intelligenz in der Qualität” in den folgenden Fachbeiträgen:
- Teil 1: Künstliche Intelligenz in der Qualität – Bestehendes Know-how effektiv nutzen – zum Beitrag »
- Teil 2: Künstliche Intelligenz in der Qualität – Welche Qualifikationen werden benötigt? – zum Beitrag »
- Teil 3: Künstliche Intelligenz in der Qualität – Praktische Einführung durch iteratives Vorgehen – zum Beitrag »
Über den Autor:
Dr.-Ing. Stefan Prorok ist Geschäftsführer der Prophet Analytics GmbH und DGQ-Trainer für Qualitätssicherung und Künstliche Intelligenz. Prophet Analytics unterstützt Unternehmen in allen Phasen Ihrer KI-Umsetzung mit Trainings- und Beratungsangeboten. Kontakt: ki@prophet-analytics.de


