
Neues FQS-Forschungsprojekt IDaP+: Ganzheitliche Steuerung bei Gussbauteilen in der Automobilindustrie
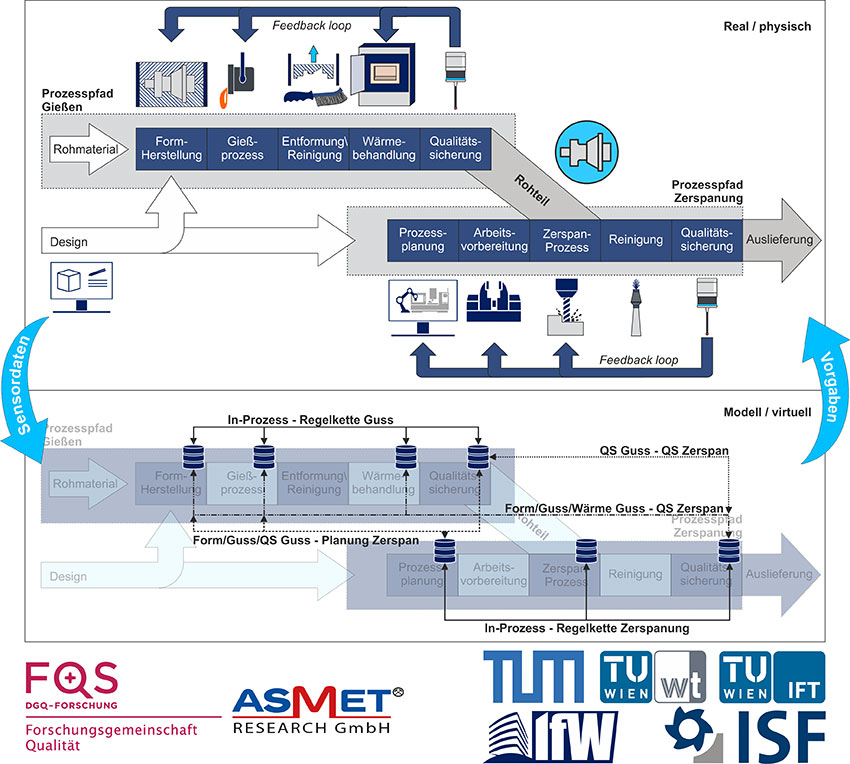
Bauteile oder Komponenten, die aus Leichtmetallen gegossen werden, spielen aufgrund von Eigenschaften wie Gewicht, Festigkeit sowie einer guten Korrosionsbeständigkeit und Verarbeitbarkeit eine wesentliche Rolle in der modernen Fertigung. Das Forschungsprojekt IDaP+ zielt auf eine ganzheitliche Regelung der Prozesskette für die Herstellung und Bearbeitung von Leichtmetallgussprodukten ab. Dies ist insbesondere für die Produktion elektrischer Antriebe in der Automobilindustrie aber auch für andere Branchen von Bedeutung. Beteiligt sind Wissenschaftler:innen der Universität Stuttgart, TU Dortmund, TU München und TU Wien. Das deutsch-österreichische Forscher:innenteam will dazu Produktionsinformationen aus verteilten und heterogenen Datenquellen nutzbar machen, um die Effizienz, Qualität und Belastbarkeit der Prozessketten zu optimieren. Unternehmen sollen auf diese Weise Einblicke und ein besseres Verständnis zur Implementierung innovativer Digitalisierungssysteme und Prozessverbesserungen in der betrachteten Prozesskette erhalten.
Rund 40 Unternehmen aus Deutschland und Österreich, die an der gesamten Wertschöpfungskette vom Gießen über die Wärmebehandlung bis hin zur spanenden Bearbeitung beteiligt sind, begleiten die Forschungsarbeiten als Industriepartner im Projektbegleitenden Ausschuss. Die enge Zusammenarbeit zwischen Wissenschaft und Industrie stellt sicher, dass die Forschungsarbeiten praxisnah und an die Bedürfnisse der Unternehmen angepasst sind.
Über das Forschungsprojekt:
Das CORNET-Vorhaben 369 EN der FQS – Forschungsgemeinschaft Qualität e. V., August-Schanz-Straße 21A, 60433 Frankfurt am Main wird im Rahmen des Programms zur Förderung der Industriellen Gemeinschaftsforschung (IGF) durch das Bundesministerium für Wirtschaft und Klimaschutz (BMWK) aufgrund eines Beschlusses des Deutschen Bundestages gefördert.
Die Koordinierung auf österreichischer Seite erfolgt über die Austrian Society for Metallurgy and Materials (ASMET).
Weitere Informationen zum Projekt und zu Beteiligungsmöglichkeiten können über die Geschäftsstelle der FQS bezogen werden:
FQS – Forschungsgemeinschaft Qualität e. V.
August-Schanz-Straße 21A
60433 Frankfurt am Main
Industriepartner für FQS-Forschungsvorhaben gesucht: Fuzzy Empfehlungsassistenten zur Fehlerbeseitigung in der Zuliefererkette
Im Verlauf der letzten Jahre haben die Spannungen zwischen Original Equipment Manufacturer (OEM) und kleinen und mittleren Unternehmen (KMU) in Zuliefererketten stark zugenommen. Die Beziehungen sind durch mangelhafte oder gänzlich fehlende Kooperation und Kommunikation, sowie ungleiche Machtgefüge geprägt. Dies führt zu Problemen in der Fehlerbewältigung. Tritt ein Fehler im Feld auf, wird dieser zwecks Ursachenidentifikation und Definition von Abstellmaßnahmen in die Zuliefererkette gegeben. Zumeist sucht jeder Zulieferer eigenverantwortlich nach den möglichen Fehlerursachen und Lösungsmaßnahmen. Die derzeitig verwendeten Methoden zur Dokumentation und Analyse von Fehlern sind der 8D-Report, das SCOR-Modell und der NTF-Prozess des Schadteilanalyseprozesses des Verbands der Automobilindustrie (VDA). Der Einsatz dieser Methoden ist jedoch zum einen mit einem hohen Zeit- bzw. Personalaufwand verbunden und zum anderen wird nicht geregelt, wie und an wen die Ergebnisse kommuniziert werden sollen. Die Kommunikation der Ergebnisse hat jedoch eine hohe Relevanz für einen effizienten Umgang mit aufgetretenen Fehlern in Zulieferketten. Im Rahmen des geplanten Forschungsprojekts FuFeZ soll dieser Handlungsbedarf mittels eines KI-basierten Referenzmodells gedeckt werden, welches eine zielgerichtete Kommunikation zwischen OEM und KMU ermöglicht.
Das Projektvorhaben FuFeZ
Ziel des avisierten Forschungsprojekts ist die Entwicklung eines Referenzmodells zum erleichterten Umgang mit Feld-Fehlern in Zuliefererketten, unterstützt durch zwei KI-basierte Empfehlungsassistenten. Während ein Assistent potenzielle Fehlerursachen vorschlägt, kommuniziert der zweite Assistent daraus resultierende konkrete Maßnahmen zur Fehlerbehebung. Unternehmen sollen in der Lage sein, das Referenzmodell und die Empfehlungsassistenten eigenständig anzuwenden.
Im Folgenden ist eine vorläufige Ideenskizze des Referenzmodells zu sehen (Abb. 1):
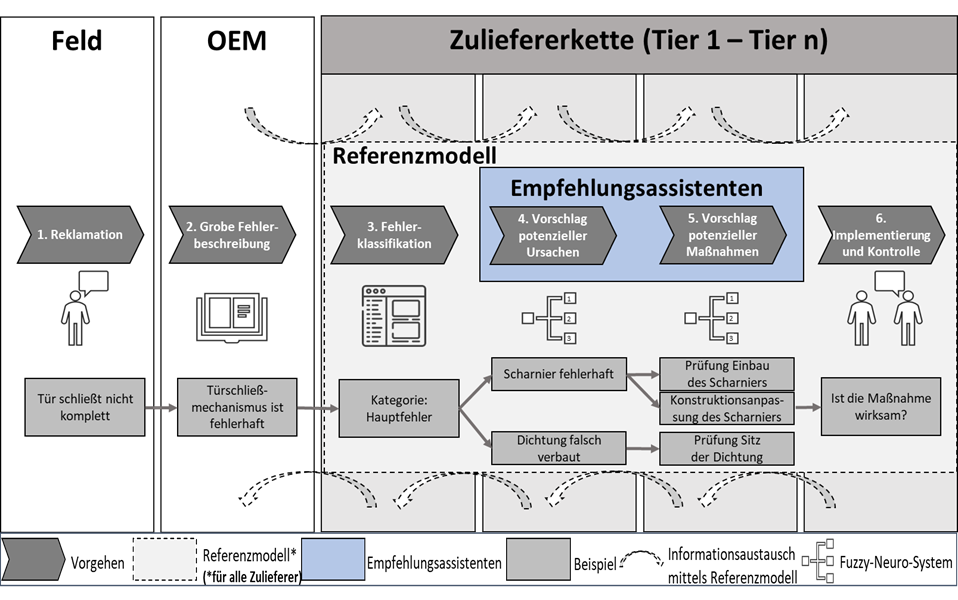
Abb. 1: Ideenskizze vom neuen Referenzmodell
Im ersten Schritt werden die Kundenreklamationen durch die Werkstätten oder den OEM selbst aufgenommen. Als Nächstes ist es die Aufgabe des OEMs die Fehlerbeschreibung durchzuführen, wobei eine Mindestanzahl an Daten vom OEM preisgegeben werden muss. Diese zwei Schritte sind erforderlich, damit die Fehlerklassifikation mittels einer zu entwickelnden Schablone (Klassifikations-Template) umgesetzt werden kann. Dadurch sind insbesondere KMU in der Lage zu ermitteln, ob für sie ein Handlungsbedarf besteht. Im Anschluss werden den Unternehmen potentielle Fehlerursachen mittels des Empfehlungsassistenten (Fuzzy-Neuro-System) vorgeschlagen. Durch einen zweiten Empfehlungsassistenten werden Maßnahmen zur Abstellung der ausgewählten Fehlerursache empfohlen. Diese allgemeinen Maßnahmen dienen als Ansatz zur Orientierung, sodass KMU Methoden zur Ursachen- und Maßnahmenbestimmung nicht mehr selbstständig durchführen müssen, wodurch sich Zeit und Personal einsparen lassen. Ergänzt werden sollen die Maßnahmen durch statische Empfehlungen. Hierbei wird zusätzlich die Information ausgegeben, welche Voraussetzungen vor der Durchführung der eigentlichen Maßnahme erfüllt sein müssen. Im Anschluss an die Durchführung der Maßnahmen wird ihre Wirksamkeit ermittelt.
Welche Vorteile hat FuFeZ für Unternehmen?
Durch die Anwendung des Referenzmodells und die vorgeschlagenen Fehlerursachen sowie Abstellmaßnahmen der Empfehlungsassistenten kann die Erkennungs- und Behebungszeit bei auftretenden Feld-Fehlern in Zuliefererketten deutlich gesenkt werden. Des Weiteren bietet FuFeZ mit seiner benutzerfreundlich gestalteten Software Unternehmen die Möglichkeit, die geeignetste Fehlerursache und (Abstell-)Maßnahme für die Fehlerbeschreibung mit geringem Aufwand aus dem vorgeschlagenen Katalog auszuwählen und gegebenenfalls. anzuwenden. Auf diese Weise können Unternehmen Fehlerkosten durch korrekte und schnelle Behandlung von Fehlerereignissen minimieren, nachhaltige Wettbewerbsvorteile erlangen und einen KI-basierten sowie digitalisierten Reifegrad erreichen. Weitere Ziele sind die Verringerung der Belastung und Beanspruchung von Mitarbeitenden im Fehlermanagementprozesses und der Aufbau einer positiven Fehlerkultur.
Diese Vorteile werden erreicht durch:
- Entwicklung eines neuen Referenzmodells, welches den aktuellen Forschungsstand abbildet, als auch den praktischen Bedarf der Unternehmen in Zuliefererketten widerspiegelt.
- Sicherstellung zur unternehmensübergreifenden Kommunikation durch KI-basierte Empfehlungen des Referenzmodells.
- Entwicklung eines Klassifikations-Templates zur konkreten Fehlerbeschreibung durch beziehungsweise für die Zulieferer.
- Entwicklung von Ursachen- und dazugehörigen Maßnahmenvorschlägen durch jeweils einen Empfehlungsassistenten, welcher durch Fuzzy-Neuro-Systeme determiniert und kontinuierlich gepflegt werden soll.
Bei Berücksichtigung dieser vier Punkte können die Unternehmen effizienter mit Feld-Fehlern in Zuliefererketten umgehen.
Wie können sich Unternehmen am Projektvorhaben beteiligen?
Das geplante Forschungsprojekt wird durch das Fachgebiet Qualitätswissenschaft der Technischen Universität Berlin initiiert und von der FQS Forschungsgemeinschaft Qualität e. V mit Mitteln des Bundesministeriums für Wirtschaft und Klimaschutz (BMWK) gefördert.
Interessierte Unternehmen, insbesondere KMU, haben die Möglichkeit, sich als Mitglied des Projektbegleitenden Ausschusses zu beteiligen. Hierbei wirken sie bei der Steuerung des Projektes und bei der Beratung der Forschungseinrichtung mit und profitieren frühzeitig von den erzielten Ergebnissen. Hierzu kann auch eine prototypische Umsetzung im Unternehmen durch die Forschungseinrichtung gehören. Detailliertere Informationen zum Vorhaben und Beteiligungsmöglichkeiten finden sich im Projektsteckbrief.

Über den Autor: Turgut Refik Caglar
Als wissenschaftlicher Mitarbeiter und Doktorand am Fachgebiet Qualitätswissenschaft der TU Berlin erforscht Turgut Refik Caglar, wie sich KI-Algorithmen durch ständige Kommunikation mit Mitarbeitenden weiterentwickeln und zu kontinuierlichen Prozessverbesserungen beitragen können. Dazu zählen insbesondere Forschungsbereiche wie Empfehlungssysteme, KI-basiertes Shopfloor Management, Verarbeitung natürlicher Sprache (NLP) und kognitive Algorithmen.
Kontakt:
t.caglar@tu-berlin.de
Mit dem Qualität-4.0-Reifegradmodell zur Digitalisierung des Qualitätsmanagements
Die digitale Transformation der Geschäftswelt ist in vollem Gange und umfasst auch zunehmend das Qualitätsmanagement produzierender Unternehmen. Insbesondere kleinen und mittleren Unternehmen fehlen oftmals personelle und finanzielle Ressourcen, um mit technologischen Entwicklungen Schritt zu halten und die digitale Transformation des Qualitätsmanagements anzustoßen. Aus diesem Grund widmet sich das Forschungsprojekt „Qbility – Quality 4.0 Capability Determination Model“ dieser Problemstellung. Im Rahmen des von der FQS Forschungsgemeinschaft Qualität e. V. geförderten Forschungsprojektes haben das Fraunhofer-Institut für Produktionstechnologie IPT, die Fachhochschule Südwestfalen sowie Partner aus der Industrie gemeinsam ein Qualität-4.0-Reifegradmodell erarbeitet. Das Tool ermöglicht es produzierenden Unternehmen, ihren eigenen Qualität-4.0-Reifegrad durch die Beantwortung gezielter Fragen zu bestimmen. Das Qualität-4.0-Reifegradmodell nutzt die Antworten der Unternehmen, um den individuellen Qualität-4.0-Reifegrad eines Unternehmens zu berechnen. Es stellt darüber hinaus automatisch abgeleitete Handlungsempfehlungen sowie Technologiesteckbriefe zur Verfügung, die den Unternehmen Anhaltspunkte auf dem Weg zu Qualität 4.0 liefern. Das entwickelte Qualität-4.0-Reifegradmodell wurde in ein Web-Tool überführt, welches interessierte Unternehmen kostenfrei nutzen können.
Aufbau des Qualität-4.0-Reifegradmodells
Das im Rahmen von Qbility entwickelte Qualität 4.0-Reifegradmodell setzt sich aus vier Stufen zusammen, die grundsätzlich konsekutiv aufeinander aufbauen, allerdings auch nicht immer vollständig trennscharf sind. Im Folgenden werden die einzelnen Stufen kurz beschrieben.
Stufe eins – Interne Digitalisierung
In der ersten Stufe wird die interne Digitalisierung behandelt. Hier liegt der Fokus auf dem internen Datenmanagement beziehungsweise der Analyse und Nutzung unternehmens- oder abteilungsinterner Daten. Dazu muss in einem ersten Schritt die Datenakquisition umgesetzt werden. Dementsprechend werden in dieser Stufe qualitätsrelevante interne Daten identifiziert, erfasst, vorverarbeitet und verwaltet. Durch das beschriebene Vorgehen beim Datenmanagement wird in dieser Stufe bereits eine interne Datengrundlage für eine zentrale QM-Datenbasis beziehungsweise Single Point of Truth geschaffen. Neben der Datenakquisition und dem Datenmanagement kann auch bereits eine retrospektiv orientierte Datennutzung stattfinden, beispielsweise durch die deskriptive und diagnostische Analyse historischer Daten zur Identifikation von Fehlerursachen.
Stufe zwei – externe Digitalisierung
In der zweiten Stufe findet eine Erweiterung des Spektrums der Daten für Datenakquisition,-management und -analyse statt. Die Daten müssen abteilungs- und unternehmensübergreifend beziehungsweise Kunden- und Lieferantenübergreifend beschafft und genutzt werden. Die Kernidee dieser Stufe ist, dass produzierende Unternehmen auch Daten nutzen müssen, die über die eigenen Unternehmensgrenzen hinausgehen. Sie können so beispielsweise Erkenntnisse darüber gewinnen, wie Kunden ihre Produkte nutzen. Die in dieser Stufe gewonnenen Daten erweitern die in Stufe eins aufgebaute interne Datengrundlage um abteilungs- oder unternehmensexterne Daten. Wie in der ersten können auch in dieser Stufe bereits erste deskriptive und diagnostische Datenanalysen stattfinden.
Stufe drei – zentrale QM-Datenbasis/Offene Systemarchitektur
In der dritten Stufe steht die Schaffung einheitlicher Datenstrukturen über alle Systeme sowie über Bereichs- und Unternehmensgrenzen hinweg im Fokus. Hier findet eine Aggregation und Synchronisation zur Nutzbarmachung der durch die interne und externe Digitalisierung gewonnen Daten statt, die in einem Single Point of Truth resultieren. Der Single Point of Truth stellt eine offene, gemeinsame Datenbasis als Kernelement von Qualität 4.0 zur Unterstützung abteilungs- und unternehmensübergreifender Zusammenarbeit dar. Er schafft somit die Grundlage für ein datenbasiertes, softwaregestütztes, agiles und kollaboratives Qualitätsmanagementsystem.
Stufe vier – prädiktives und präskriptives QM
Ausgehend von der zentralen QM-Datenbasis wird in der vierten Stufe ein prädiktives und präskriptives QM umgesetzt. Prädiktiv beschreibt dabei die Fähigkeit, in der Zukunft liegende Ereignisse vorauszusagen, beziehungsweise die Wahrscheinlichkeit des Eintretens dieser Ereignisse abzuschätzen. Mit präskriptiven Methoden sind Verfahren gemeint, die beispielsweise mittels Simulationen Bewertungen und Vergleiche verschiedener Zukunftsszenarien und Handlungsalternativen ermöglichen. Auf diese Weise kann datenbasiert abgeschätzt werden, welche Auswirkungen bestimmte Entscheidungen haben. In der vierten Stufe stehen dementsprechend datenbasierte prädiktive und präskriptive Produkt- und Prozessoptimierungen im Vordergrund. Auf diese Weise können beispielsweise Simulationen und Vorhersagen auf einer breiten Datenbasis erstellt und für die Vorhersage in der Zukunft möglicherweise auftretender Qualitätsfehler genutzt werden. Im Vergleich zu den Stufen eins und zwei verlagert sich der Schwerpunkt der Datenanalyse: während in Stufe eins und zwei die retrospektiv orientierten deskriptiven und diagnostischen Datenanalysen betrieben werden, werden in der vierten Stufe prädiktive und präskriptive Datenanalysen umgesetzt, die Aussagen über die Eintrittswahrscheinlichkeit zukünftiger Ereignisse ermöglichen.
Die Berechnung des individuellen Qualität-4.0-Reifegrades eines Unternehmens erfolgt in verschiedenen Phasen, die entlang des Produktlebenszyklus aufgeteilt sind. Auf diese Weise kann beispielsweise ermittelt werden, ob ein Unternehmen in der Planungs- und Konzeptionsphase hinsichtlich Qualität 4.0 schon recht weit ist, dafür aber eventuell in den Bereichen Produktion oder Beschaffung noch Aufholbedarf besteht.
Blick in die industrielle Praxis
Die Viega GmbH & Co. KG hat sich innerhalb des Forschungsprojektes intensiv an der Mitentwicklung des Reifegradmodells als Industriepartner beteiligt. Durch die Beschreibung unternehmensinterner Entwicklungsvorgänge hat das Unternehmen Impulse für eine industrienahe Ausrichtung des Qualität 4.0-Reifegradmodells geliefert.
Im Folgenden beschreibt Özer Hatip, Gruppenleiter Integriertes Management, inwiefern das beschriebene Qualität 4.0-Reifegradmodell die gelebte Praxis bei Viega wiederspiegelt:
„Die ersten beiden Stufen des Reifegradmodells sind bei Viega nicht scharf voneinander getrennt und verschwimmen im Grunde zu einer Stufe. Dies ist durch die Nutzung industrieller Softwaresysteme wie beispielsweise SAP oder CAQ bedingt. Dokumente wie Wareneingangsprüfpläne und Lieferantenbewertungen liegen bei uns in digitaler Form vor, sodass wir keine Unterscheidung mehr zwischen ‚interner‘ und ‚externer‘ Digitalisierung vornehmen müssen. Allerdings ist in der Zusammenarbeit mit externen Partnern diese Unterscheidung eindeutig spürbar. Insbesondere kleinere Unternehmen verfügen oftmals nicht über die notwendigen Infrastrukturen und Softwaresysteme, in denen interne und externe Daten verfügbar sind. Die Unterscheidung in interne und externe Digitalisierung ist also insbesondere im Hinblick auf KMU durchaus sinnvoll, auch wenn sie bei einigen größeren Unternehmen nicht mehr vollumfänglich gültig ist.
In den vergangenen Jahren hat Viega eine starke Entwicklung in Richtung der Reifegradstufe drei des Qualität-4.0-Reifegradmodells vollzogen. Qualitätsbezogene Daten, Prozess- und Produktdaten werden mit weiteren relevanten Daten (wie zum Beispiel Energieverbrauchsdaten) angereichert und zentral in offenen Datenbanksystemen verfügbar gemacht (sogenannte Data Lakes). Diese Daten werden anschließend genutzt, um beispielsweise ein ‚Real-time Monitoring‘ der Produktion zu ermöglichen, indem KPI in Echtzeit zur Überwachung von Produkten und Prozessen visualisiert und ausgewertet werden. Auf diese Weise wird eine deutlich aktuellere Überwachung, Steuerung und Optimierung bestehender Prozesse ermöglicht. Weiterhin arbeitet Viega bereits in Pilotprojekten daran, prädiktive Verfahren zur Produkt- und Prozessoptimierung einzusetzen und sich somit in Richtung der vierten Stufe des Reifegradmodells zu bewegen. Die in den vergangenen Jahren aufgebaute Datenbasis stellt dabei die Grundlage dar, um den Echtzeit-Einblick in laufende Prozesse noch zu erweitern und den Blick auch auf in der Zukunft möglicherweise eintretende Ereignisse zu richten. Diese Entwicklung soll in der Zukunft weiter verstetigt und breit ausgerollt werden.“
Zusammenfassung
Zusammenfassend lässt sich sagen, dass das entwickelte Qualität-4.0-Reifegradmodell die industrielle Praxis widerspiegelt. Insbesondere kleinen und mittleren Unternehmen kann durch die selbstständige Ermittlung des eigenen Qualität-4.0 Reifegrades und der anschließenden Skizzierung möglicher Weiterentwicklungspfade der Einstieg in die digitale Transformation des Qualitätsmanagements gelingen. Das Qbility Web-Tool wird zum Ende des Projektes allen interessierten Unternehmen kostenfrei über das Internet zur Verfügung gestellt.
Über die Autoren
Maximilian Brochhaus M.Sc., Fraunhofer-Institut für Produktionstechnologie IPT
Prof. Dr.-Ing. Karsten Fleischer, Allgemeiner Maschinenbau insbes. Qualitätsmanagement, Fachhochschule Südwestfalen, Standort Hagen
Dr. Julian Koch, Fachhochschule Südwestfalen, Standort Hagen
Özer Hatip, Dipl. Wirt.-Ing., Viega GmbH & Co. KG, Gruppenleitung Integriertes Management, Viega GmbH & Co. KG
Über das Forschungsprojekt
Das IGF-Vorhaben 21232 N der Forschungsvereinigung Forschungsgemeinschaft Qualität e.V. (FQS), August-Schanz-Straße 21A, 60433 Frankfurt am Main wurde über die AiF im Rahmen des Programms zur Förderung der Industriellen Gemeinschaftsforschung (IGF) vom Bundesministerium für Wirtschaft und Klimaschutz aufgrund eines Beschlusses des Deutschen Bundestages gefördert.
Der Schlussbericht zu diesem Projekt kann ab Ende 2022 über die FQS bezogen werden. Kontakt zur Geschäftsstelle der FQS: infofqs@dgq.de
Weitere Informationen auf der Projektwebsite des Fraunhofer IPT: https://www.ipt.fraunhofer.de/de/projekte/qbility.html
FQS-Forschungsprojekt AIDpro: Datenqualität durch Prozessdatenvalidierung
Machine Learning (ML) Algorithmen ermöglichen es, aus hochdimensionalen und großen Datenmengen Informationen zu gewinnen, um die menschliche Entscheidungsfindung zu unterstützen oder autonom Entscheidungen zu treffen. In rein virtuellen Anwendungen, wie im Online-Marketing, in Suchmaschinen oder in Chatbots, macht sich ML im alltäglichen Leben bereits seit einigen Jahren deutlich bemerkbar. In der Produktionstechnik bestehen dagegen weiterhin große Schwierigkeiten, das Nutzenpotenzial von ML flächendeckend zu erschließen. Der Grund für diese Diskrepanz liegt im Spannungsfeld begründet, in dem sich produktionstechnische ML-Anwendungen befinden. Dieses herausfordernde Umfeld ist charakterisiert durch:
- die Eigenschaften realer Prozessdaten (geringe Datenqualität und hohe Datenkomplexität),
- die ML-Modelleigenschaften (stochastisch, intransparent und anfällig gegenüber Datenfehlern) und
- die hohen produktionstechnischen Anforderungen an die Zuverlässigkeit von Produktionssystemen und die damit verbundenen hohen wirtschaftlichen Risiken.
Für die Produktionstechnik liegt der Schlüssel zum Erfolg in der Datenqualität. Seit Beginn der vierten industriellen Revolution haben viele Unternehmen die Strategie verfolgt, Daten unstrukturiert in großen Mengen in der Hoffnung zu speichern, dass der Wert dieser Daten zukünftig erschlossen werden kann. Weil sich diese Datensätze heutzutage oft als nicht verwertbar herausstellen, haben sich mittlerweile alternative Datenstrategien etabliert. Sie sehen vor, dass bereits bei Datenaufnahme eine höchstmögliche Datenqualität sichergestellt werden muss.
Das Forschungs- & Entwicklungsvorhaben AIDpro
In der Produktion liegt die wesentliche Herausforderung in der Interaktion mit der realen Welt. Mithilfe von Sensorik wird versucht, den Zustand von Bauteilen, Fluiden, Prozessen oder Maschinen zu eindeutig zu bestimmen. Allerdings unterliegen die Daten Messrauschen, werden mit unterschiedlichen Frequenzen erzeugt, werden beeinflusst von Sensorfehlern, Umgebungseinflüssen und falschen Prozesseinstellungen. Sie stellen damit nur eine unsichere Abschätzung der realen Zustände dar.
Um für produzierende Unternehmen dieses Problem zu lösen, somit die Qualität von Prozessdaten sicherzustellen und dadurch das Fundament für produktionstechnische ML-Anwendungen zu legen, bündeln das Fraunhofer Institut für Produktionstechnik IPT aus Aachen und das Fraunhofer Institut für Angewandte und Integrierte Sicherheit AISEC aus München ihre Kompetenzen im Entwicklungsvorhaben AIDpro (kurz für Anomaliedetektion in der Produktion). Gefördert wird das geplante Forschungsprojekt von der FQS Forschungsgemeinschaft Qualität e.V.
Lösungsansatz
Ziel von AIDpro ist die Entwicklung einer standardisierten Datenqualitätssicherung für Produktionsprozesse mithilfe von Datenvalidierungsansätzen und KI-basierter Erkennung von anomalen Daten in enger Zusammenarbeit mit produzierenden Unternehmen. Durch eine standardisierte Sicherheitsschicht werden Prozessrohdaten validiert, indem die Daten fortlaufend überwacht und auf ihre Integrität hin überprüft werden. Ausreißer werden ermittelt und abgefangen. Auch sich zeitlich ausbildende Datendrifts, die beispielsweise aufgrund von Verschleiß eine wesentliche Herausforderung in Produktionsprozessen darstellen, sollen sich detektieren lassen.
Welchen Nutzen besitzt eine solche Lösung für Unternehmen?
Die Datenvalidierung bildet neben der Sicherstellung einer hohen Datenqualität das Fundament für die Erschließung einer Vielzahl weiterer Nutzenpotenziale im industriellen Kontext:
- Steigerung des wirtschaftlichen Werts der Daten
- Überwachung des Maschinenzustands (Fehlerhafte Daten deuten auf Fehler im Prozess hin)
- Zuverlässiger und sicherer Einsatz von ML-Modellen auf validierten Daten
- Qualitätsüberwachung (Fehlerhafte Daten deuten auf Fehler im Produkt hin)
- Präzisere Planung von Instandhaltungsmaßnahmen
Neben den technologischen Vorteilen können die Unternehmen durch einen aktiven Austausch im Konsortium ihre Kompetenzen in Digitalisierungsthemen ausbauen, eigene Themen, Fragestellungen und Anwendungsfälle mit einbringen und wichtige Kontakte zu Forschungsinstituten und Industrieunternehmen für strategische interdisziplinäre Kooperationen knüpfen.
Fazit und Ausblick
Wer das Potenzial von Prozessdaten und die damit verbundenen Effizienzvorteile voll ausschöpfen möchte, muss eine höchstmögliche Datenqualität sicherstellen. Neben mangelnder Digitalisierungskompetenzen stellt genau das eine große Herausforderung im produktionstechnischen Umfeld dar. AIDpro ist auf der Suche nach Unternehmen, die daran interessiert sind – ausgehend von der Umsetzung einer ML-Pilotanwendung auch weitere Herausforderungen der Prozessdigitalisierung gemeinsam mit dem Projektbeteiligten zu lösen. Detailliertere Informationen zum Vorhaben und Beteiligungsmöglichkeiten finden sich im Projektsteckbrief.

Über den Autor: Lars Leyendecker
Als wissenschaftlicher Mitarbeiter und Doktorand am Fraunhofer Institut für Produktionstechnologie IPT in Aachen erforscht Lars Leyendecker, wie mithilfe von datengetriebener Optimierung Effizienzpotentiale in produktions- und medizintechnischen Anwendungen erschlossen werden können. Dazu zählen insbesondere Themen wie Erklärbarkeit, Stabilität, Robustheit und Adaptionsfähigkeit von ML-Systemen.
Kontakt:
Fraunhofer-Institut für Produktionstechnologie IPT
Lars Leyendecker
lars.leyendecker@ipt.fraunhofer.de
Alexander Kreppein
alexander.kreppein@ipt.fraunhofer.de
FQS – Forschungsgemeinschaft Qualität e. V.
August-Schanz-Straße 21A
60433 Frankfurt am Main
infofqs@dgq.de

