
Verbesserung der Vorhersagequalität von KI-Modellen mittels GANs (Generative Adversarial Neural Networks)

Die immer weiter steigende Leistungsfähigkeit von Convolutional Neural Networks (CNN) macht diese Architekturen für verschiedene Bildverarbeitungsaufgaben immer attraktiver. Sie werden nun verstärkt im Bereich der Bildverarbeitung eingesetzt. Insbesondere bei Bildklassifikationsaufgaben löst diese Technologie klassische analytische Bildverarbeitungsansätze ab. Steigende Datenverfügbarkeit und zunehmende Rechnerkapazitäten ermöglichen die hohe Leistungsfähigkeit und Anwendbarkeit dieser Modellarchitekturen.
Funktionsweise und Konzeption von CNNs
Bei der Bildklassifikation wird ein Eingangsbild entsprechend einer Menge von möglichen Klassen zugeordnet. Durch einen Trainingsprozess mit einer ausreichenden Datenmenge werden die Parameter der Modellarchitekturen so angepasst, dass sie die gestellte Aufgabe mit möglichst wenigen Fehlklassifikationen erfüllen können. Die Modelle lernen aus den Daten. Bekannte Bildklassifizierungsarchitekturen wie AlexNet1, VGG-162, ResNet3, Inception-V34 und Efficientnet5 nehmen ein Eingangsbild und leiten es dann durch mehrere Schichten. Aufgrund der hohen Anzahl an Parametern dieser Architekturen wird eine große Menge an repräsentativen Daten benötigt, um ihre Leistung und Generalisierungsfähigkeit zu verbessern.
Die Architekturen sind in der Regel so konzipiert, dass sie mit ausgewogenen Datensätzen gut funktionieren. Ein häufig auftretendes Problem bei realen Datensätzen ist, dass sie unter einem Ungleichgewicht der Klassen leiden. Bei der Qualitätskontrolle in der Produktion steht oft nur eine kleine Anzahl von Defektbildern zum Trainieren der CNNs zur Verfügung, wohingegen viele Gutbilder vorhanden sind. Dies führt zu dem Problem, dass die Netze allein auf Grund der Unausgewogenheit der Daten dann dazu neigen, ein Bild eher als Gutbild zu klassifizieren als als Defektbild, da dieser Vorgang im Trainingsprozess meist zu einer korrekten Klassifizierung führte und somit mit einem kleinen Loss belohnt wurde.
Gängige Ansätze Klassenungleichgewicht auszugleichen
Es gibt verschiedene Methoden dieses Ungleichgewicht zu reduzieren oder zu kompensieren. Eine häufig verwendete Methode ist die Datenaugmentierung. Dabei werden leicht modifizierte Kopien von bereits vorhandenen Daten erstellt und zu der entsprechenden Klasse hinzugefügt. Eine weitere Möglichkeit ist die Anpassung der Gewichtung. In diesem Fall werden Fehlklassifikationen von Instanzen aus Klassen mit wenig Daten stärker gewichtet.
Fähigkeiten und Möglichkeiten von Generative Adversarial Networks
Im Gegensatz zu den genannten Ansätzen zielen Generative Adversarial Neural Networks (GANs) in diesem Kontext darauf ab, die zugrundeliegenden Datenverteilungen aus den begrenzten verfügbaren Bildern zu lernen und dann die gelernten Verteilungen zu verwenden, um synthetische Bilder zu erzeugen. Dies wirft die interessante Frage auf, ob GANs verwendet werden können, um synthetische Bilder für Klassen mit wenig Bilddaten verschiedener unausgeglichener Datensätze zu erzeugen. Sie könnten somit als eine intelligente Oversampling-Methode verwendet werden. GANs sind nicht nur in der Lage ein synthetisches Bild zu generieren, sondern bieten auch eine Möglichkeit, etwas am Originalbild zu verändern.
Wie funktionieren GANs?
Generative Adversarial Networks bestehen aus zwei künstlichen neuronalen Netzen. Ein Netz ist der sogenannte Generator, der aus einem Vektor latenter Variablen künstliche Daten erzeugt. Das zweite Netz ist der Diskriminator, der die Daten auswertet und versucht, zwischen künstlichen und realen Daten zu unterscheiden. Diese beiden Netzwerke führen im Trainingsprozess ein Nullsummenspiel durch6.
Der Generator versucht, Daten zu erzeugen, die den realen Daten so ähnlich sind, dass der Diskriminator nicht in der Lage ist, die künstlich erzeugten Daten von den realen Daten zu unterscheiden. Abbildung 1 zeigt eine schematische Darstellung einer klassischen GAN-Architektur.
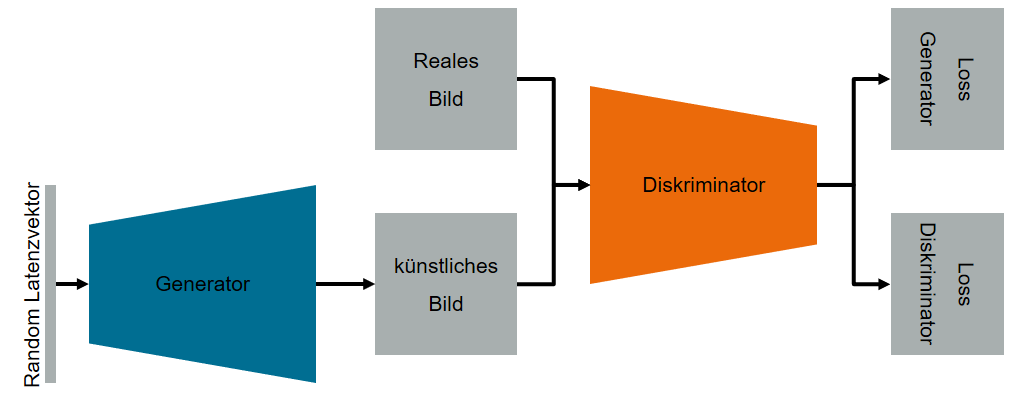
Abbildung 1: Schematische Darstellung einer klassischen GAN-Architektur. Quelle: Janek Stahl
Die ersten GAN-Architekturen benötigten eine große Menge an Daten für die Trainingsphase und konnten nur Bilder mit begrenzter Auflösung erzeugen. Neuere Architekturen wie SinGAN7 oder StyleGAN28, die mit Adaptive Discriminative Augmentation (ADA) arbeiten, erlauben es jedoch, auch mit kleinen Datensätzen hochwertige Bilder zu erzeugen.
Realistische Bilder auch bei begrenzten und unausgewogenen Datensätzen
Um eine möglichst realitätsnahe Situation zu simulieren, wurde ein Teildatensatz des MVTech Anomaly Detection Datensatzes9 betrachtet. Im Speziellen wurde der Datensatz „carpet“ und der Datensatz „hazelnut“ für Untersuchungen mit GAN-Architekturen verwendet. Jeder Datensatz enthält fehlerfreie Bilder der Klasse „no-defect“ und Bilder mit Anomalien der Klasse „defect“. Die Bilder wurden so aufgeteilt, dass im Trainingsdatensatz nur 10 Bilder der Minoritäten-Klasse „defect“ und 280 Bilder der Klasse „no-defect“ vorliegen. Somit handelt sich also um stark unausgeglichene Datensätze.
In einer ersten Untersuchung wurde die SinGAN-Architektur verwendet. Diese Architektur ist in der Lage, durch Training mit nur einem Bild künstliche Bilder zu erzeugen. Nach einer Trainingszeit von nur sechs Stunden war das Modell in der Lage, realistische Defektbilder des Datasets „carpet“ zu erzeugen. Für das komplexere Objekt Haselnuss des Datasets „hazelnut“ war dies mit dieser Architektur nicht möglich.
In einer zweiten Untersuchung wurde die StyleGAN2-Architektur verwendet. Hier wurde das Netz mit den 280 Bildern ohne Anomalien und mit den 10 Bildern mit Anomalien trainiert. Nach einer Trainingszeit von etwa einer Woche war die Architektur in der Lage, qualitativ hochwertige Bilder zu generieren. Dies gelang sowohl für den „carpet“- als auch für den „hazelnut“-Datensatz. Tabelle 1 zeigt reale Bilder der Datensätze und künstlich erzeugte Bilder der Datensätze.

Tabelle 1: Echte Bilder des Datensatzes und künstlich generierte Bilder der Datensätze.
Künstliche Bilder der Minoritäten-Klasse „defect“ wurden dann dem Trainingsset der CNNs hinzugefügt. Die Auswertungen der trainierten CNN-Modelle hat gezeigt, dass die CNNs, welche mit künstlich generieten Bilder in der Klasse „defect“ trainiert wurden eine höhere Vorhersagezuverlässigkeit aufweisen als die CNNs, welche ohne die künstlich generierten Bilder trainiert wurden.
Zusammenfassung
Diese Untersuchung hat gezeigt, wie einige der neuesten GAN-Architekturen in der Lage sind, selbst bei begrenzten und unausgewogenen Datensätzen qualitativ hochwertige Bilder zu erzeugen. Der Einsatz dieser Architekturen kann dazu beitragen, das Zuverlässigkeitsniveau von automatischen Systemen zur Anomalieerkennung auf Basis von Deep Learning zu erhöhen. Tatsächlich kann die Integration von synthetisch erzeugten Bildern in den Datensatz es ermöglichen, das Genauigkeitsniveau des Qualitätsprüfungssystems auch in Kontexten zu erhöhen, in denen es aufgrund der geringen Häufigkeit von Anomalien schwierig ist, eine große Menge an ausgewogenen realen Daten zu generieren.
Literaturverzeichnis
[1] Alex Krizhevsky, Sutskever, I. and Hinton, G. E., [ImageNet Classification with Deep Convolutional Neural Networks], Curran Associates, Inc, 1097–1105 (2012).
[2] Simonyan, K. and Zisserman, A., [Very Deep Convolutional Networks for Large-Scale Image Recognition] (9/4/2014).
[3] He, K., Zhang, X., Ren, S. and Sun, J., “Deep residual learning for image recognition,“, 770–778.
[4] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. and Wojna, Z., “Rethinking the inception architecture for computer vision,“, 2818–2826 (2016).
[5] Tan, M. and Le, Q., “Efficientnet: Rethinking model scaling for convolutional neural networks,“, 6105–6114 (2019).
[6] Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A. and Bengio, Y., “Generative adversarial networks,“ arXiv preprint arXiv:1406.2661 (2014).
[7] Shaham, T. R., Dekel, T. and Michaeli, T., “Singan: Learning a generative model from a single natural image,“, 4570–4580 (2019).
[8] Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J. and Aila, T., “Analyzing and improving the image quality of stylegan,“, 8110–8119 (2020).
[9] Bergmann, P., Fauser, M., Sattlegger, D. and Steger, C., “MVTec AD‐A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection,“, 9592–9600 (2019).
Über die Autoren:
Janek Stahl ist seit 2015 als wissenschaftlicher Mitarbeiter am Fraunhofer-Institut für Produktionstechnik und Automatisierung tätig. Seit seinem Maschinenbaustudium an der Universität Stuttgart arbeitet er dort in der Abteilung Bild- und Signalverarbeitung, wo er sich verstärkt mit maschinellen Lernverfahren für die 2D-Bildverarbeitung im industriellen Umfeld beschäftigt.
Omar De Mitri ist seit 2019 wissenschaftlicher Mitarbeiter am Fraunhofer-Institut für Produktionstechnik und Automatisierung. Seit Abschluss seines Studiums des Computer Engineering an der Universität Salento (Italien) arbeitet er dort in der Abteilung Bild- und Signalverarbeitung. Sein besonderes Interesse gilt dem maschinellen Lernen mit Schwerpunkt im Bereich Computer Vision und Mustererkennung.
