
Deep Reinforcement Learning für sichere Mensch-Maschine-Kollaboration

Im Zeitalter zunehmender Automatisierung und Digitalisierung, Industrie 4.0, Produktindividualisierung und globaler Vernetzung müssen auch Mensch und Maschine immer enger zusammenarbeiten, um optimale Produktivität der Produktionsprozesse zu garantieren. Je nach Anwendungsbereich können Mensch und Roboter unterschiedlich eng zusammenarbeiten. Auch wenn der Begriff „Mensch-Roboter-Kollaboration (MRK)” geläufig ist, kann das „K” in MRK für verschiedene Ausprägungen der Zusammenarbeit stehen.
Bei der Koexistenz arbeiten Mensch und Roboter ohne Schutzzaun in benachbarten Arbeitsbereichen. Sie teilen sich jedoch keinen gemeinsamen Arbeitsraum und arbeiten unabhängig voneinander an unterschiedlichen Aufgaben.
Bei der Mensch-Roboter-Kooperation arbeiten Mensch und Roboter im gleichen Arbeitsraum. Sie bearbeiten zeitversetzt unterschiedliche Aufgaben eines Prozesses. Es findet keine direkte Interaktion statt.
Bei der Kollaboration interagieren Mensch und Roboter in einem gemeinsamen Arbeitsraum miteinander. Beispielsweise reicht der Roboter dem Menschen etwas an oder sie führen gleichzeitig unterschiedliche Aufgaben am selben Bauteil durch.

Abbildung 1: Mensch-Maschine-Kollaboration
Herausforderungen Mensch-Roboter-Kollaboration
Bei der Kollaboration von Mensch und Roboter muss gewährleistet sein, dass jede Interaktion absolut sicher ist, das heißt der Mensch zu keiner Zeit einer Gefährdung ausgesetzt ist. Mit der steigenden Effizienz moderner Methoden aus dem Bereich der Künstlichen Intelligenz (KI), insbesondere in dem Teilgebiet des Maschinellen Lernens, werden diese Verfahren auch vermehrt im Umfeld der Produktion eingesetzt. Deep Reinforcement Lernalgorithmen versetzen Roboter in die Lage, Sicherheitsstrategien innerhalb einer Simulationsumgebung nach dem Prinzip der Belohnung und Bestrafung zu lernen. Wegen ihres enormen Potentials für die Mensch-Maschine Kollaboration wird in diesem Bereich derzeit viel Forschung betrieben.
Maschinelles Lernen durch Belohnung
Deep Reinforcement Learning ist eine Methode aus dem Bereich des Maschinellen Lernens, bei der ein Agent selbständig eine Strategie erlernt, um erhaltene Belohnungen zu maximieren. Dabei wird dem Agenten nicht vorgegeben, welche Aktion in welcher Situation die beste ist, sondern er erhält zu bestimmten Zeitpunkten eine Belohnung, die auch negativ sein kann (Bestrafung). Anhand dieser Belohnungen wird versucht, eine Nutzenfunktion zu maximieren, die beschreibt, welchen Wert ein bestimmter Zustand oder Aktion hat.
Die Begriffe „Agent“, „Beobachtung“, „Umgebung“, „Aktion“ und „Belohnung“ sind hierbei von zentraler Bedeutung. Sie lassen sich folgendermaßen definieren:
- Der Agent entscheidet, welche Aktionen auszuführen sind auf Basis der Belohnung und den Beobachtungen. Der Roboter ist hierbei der Agent.
- Eine Beobachtung ist eine Information aus der Umgebung, die an den Agenten übermittelt wird. Die Geschwindigkeit des Greifers, die Position des Greifers oder die Position des Hindernisses sind Beispiele für Beobachtungen.
- Die Umgebung wird durch die Aktionen des Agenten beeinflusst und generiert Beobachtungen sowie eine Belohnung für den Agenten (Alle relevanten Informationen aus dem Anwendungsbereich bilden die Umgebung).
- Eine Aktion wird vom Agenten ausgeführt und ändert den Zustand der Umgebung. Beispielsweise ist die Bewegung des Greifers eine Aktion.
- Die Belohnung wird dem Agenten rückgemeldet und besagt, wie gut der Agent in diesem Schritt ist. Die Belohnung wird an den Agenten übermittelt.
Die einzelnen Interaktionen sind in Abbildung 2 noch einmal graphisch dargestellt.
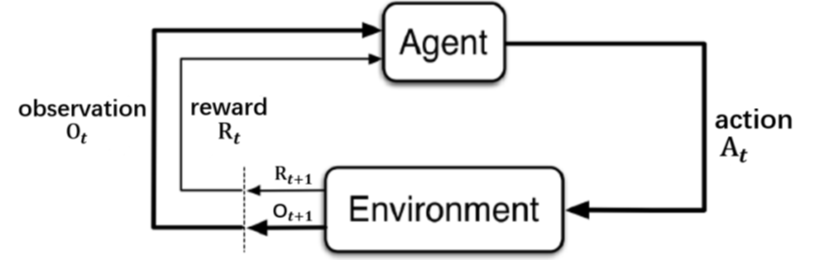
Abbildung 2: Die Interaktionen zwischen dem Agent und der Umgebung bei einem Reinforcement Learning Ansatz
Es sei noch ausdrücklich darauf hingewiesen, dass der Reinforcement Learning Ansatz zur Kollisionsvermeidung nur in einer Simulationsumgebung stattfindet.
Bayes’sche Modelle validieren Lernverfahren
Der Reinforcement Lernalgorithmus gehört der Klasse der Künstlichen Neuronalen Netzen (KNN) an. Da solche Netze zu den Black-Box-Algorithmen gehören, ist es wichtig, deren Ergebnisse in geeigneter Form zu bestätigen beziehungsweise zu validieren.
Bayes’sche Netze stellen einen Formalismus zum Schließen bei unsicherem Wissen dar. Sie bestehen aus einem gerichteten azyklischen Graph, in dem die Knoten Variablen und die Kanten Abhängigkeiten zwischen diesen Knoten repräsentieren. Diese Abhängigkeiten werden mit Wahrscheinlichkeitswerten quantifiziert.
Bayes’sche Netze mit einem Vorgängerknoten, der Wurzel, sowie n Nachfolgerknoten werden zur Klassifikation benutzt. Man nennt sie deshalb auch Bayes’sche Klassifikatoren. Hierbei stellen die Wurzeln die Klassifkationsvariable und die Nachfolger die Attribute dar. Im vorliegenden Anwendungsfall soll versucht werden zu bewerten, ob die aktuelle Aktion des Roboters sicher ober unsicher ist. Es wird also bewertet, wie wahrscheinlich das Risiko einer Kollision des Roboters mit einem Hindernis ist.
In Abbildung 3 ist das Prinzip der Validierung des Lernverfahrens dargestellt. Es wird klassifiziert, ob durch die aktuell nächste geplante Aktion des Roboters mit hoher Wahrscheinlichkeit ein sicherer Zustand gewährleistet ist. Die Attribute sind hierbei alle Beobachtungen, die vom Roboter auszuführende Aktion sowie weitere Größen aus der Umgebung.
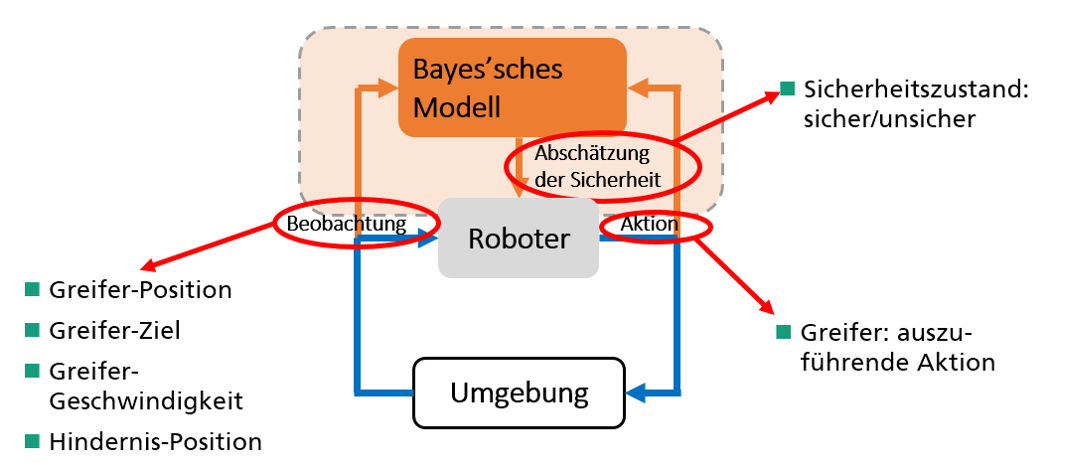
Abbildung 3: Validierung des Reinforcement Lernverfahrens mit Hilfe Bayes’scher Modelle
Es wurden drei Bayes’sche Modelle zur Validierung benutzt: der sogenannte naive Bayes’sche Klassifikator, der Tree Augmented Naive (TAN) Bayes’sche Klassifikator und ein Bayes’sches neuronales Netz. Diese werden im Folgenden bewertet und miteinander verglichen. Abbildung 4 zeigt beispielhaft den naiven Bayes’schen Klassifikator und das Bayes’sche neuronale Netz.
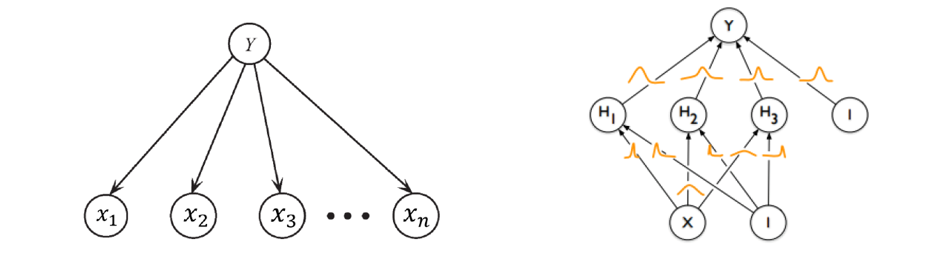
Abbildung 4: Der naive Bayes’sche Klassifikator (links) sowie das Bayes’sche neuronale Netz (rechts)
Ergebnisse und deren Bewertung
Die verschiedenen Modelle wurden mit Hilfe verschiedener Performance-Metriken bewertet und verglichen. Abbildung 5 ist zu entnehmen, dass das Bayes’sche neuronale Netz die höchste Genauigkeit erzielt, allerdings über zwanzig Minuten für das Lernen des Modells benötigt. Die beiden Bayes’schen Klassifikatoren lassen sich in weniger als einer Sekunde beziehungsweise in wenigen Sekunden lernen, sind jedoch in der Vorhersagegenauigkeit schwächer als das neuronale Netz.
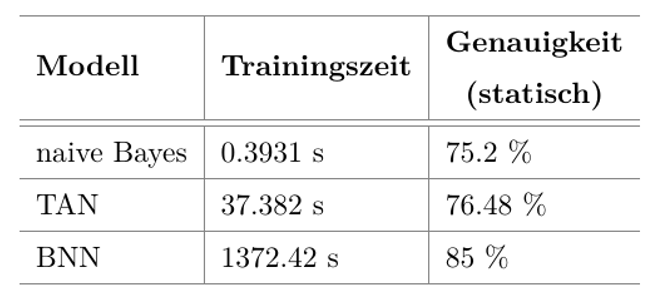
Abbildung 5: Ergebnisse der drei Validierungsmodelle für ein statisches Hindernis
Abbildung 5 zeigt die Ergebnisse für ein statisches Hindernis. Da sich der Mensch bei seinen Tätigkeiten im Allgemeinen bewegt, sind die Aussagen nur von begrenztem Nutzen. Abbildung 6 vergleicht die Ergebnisse mit denen bei einem dynamischen Hindernis, was der realen Situation sehr viel näher kommt. Es zeigt sich, dass die Ergebnisse bei dem dynamischen Hindernis nur unwesentlich schlechter sind.
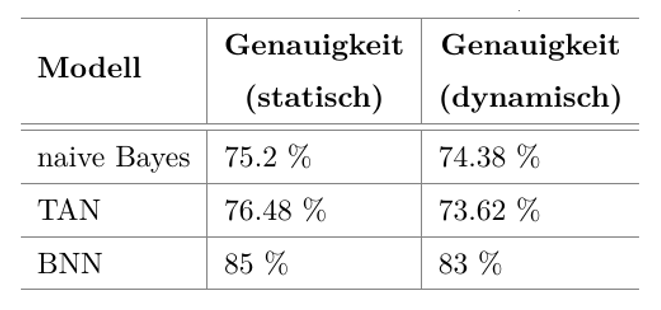
Abbildung 6: Ergebnisse der drei Validierungsmodelle für ein dynamisches Hindernis
Weitere Forschungen erforderlich
Bis die oben beschriebenen Ansätze eine kollisionsfreie Zusammenarbeit zwischen Mensch und Maschine garantieren können, bedarf es noch Forschungsarbeit. Der Reinforcement Learning Ansatz funktioniert bisher nur in der Simulation und noch nicht an einem realen Roboter. Die entwickelten Methoden zur Validierung geben bisher lediglich eine Sicherheitswahrscheinlichkeit für einen risikolosen Zustand an und müssen deshalb weiterentwickelt werden. Die Forschungsansätze sind auf jeden Fall ein Schritt in die richtige Richtung und sollten weiterverfolgt und optimiert werden.
Über den Autor:
Michael Kempf ist wissenschaftlicher Mitarbeiter am Fraunhofer Institut für Produktionstechnik und Automatisierung in der Gruppe für Qualitäts- und Zuverlässigkeitsmanagement. Seine Forschungsschwerpunkte sind statistische Methoden in den Bereichen Prozessoptimierung, Zuverlässigkeitsanalyse und Risikominimierung. Sein Spezialgebiet sind die Bayes’schen Modelle.

